
Google 今日發表了 DiffusionGemma,這是一個開源 AI 模型,其生成文字的方式類似圖像生成器建立圖片:從雜訊開始,逐步精煉直到內容合理。它在 NVIDIA H100 上能達到每秒 1,000 個 token 的速度。(Token 是 AI 模型處理資訊的基本單位。)這意味著它比一般的 Gemma 快上四倍。它也是免費的,採用 Apache 2.0 授權,模型權重已上傳至 Hugging Face。
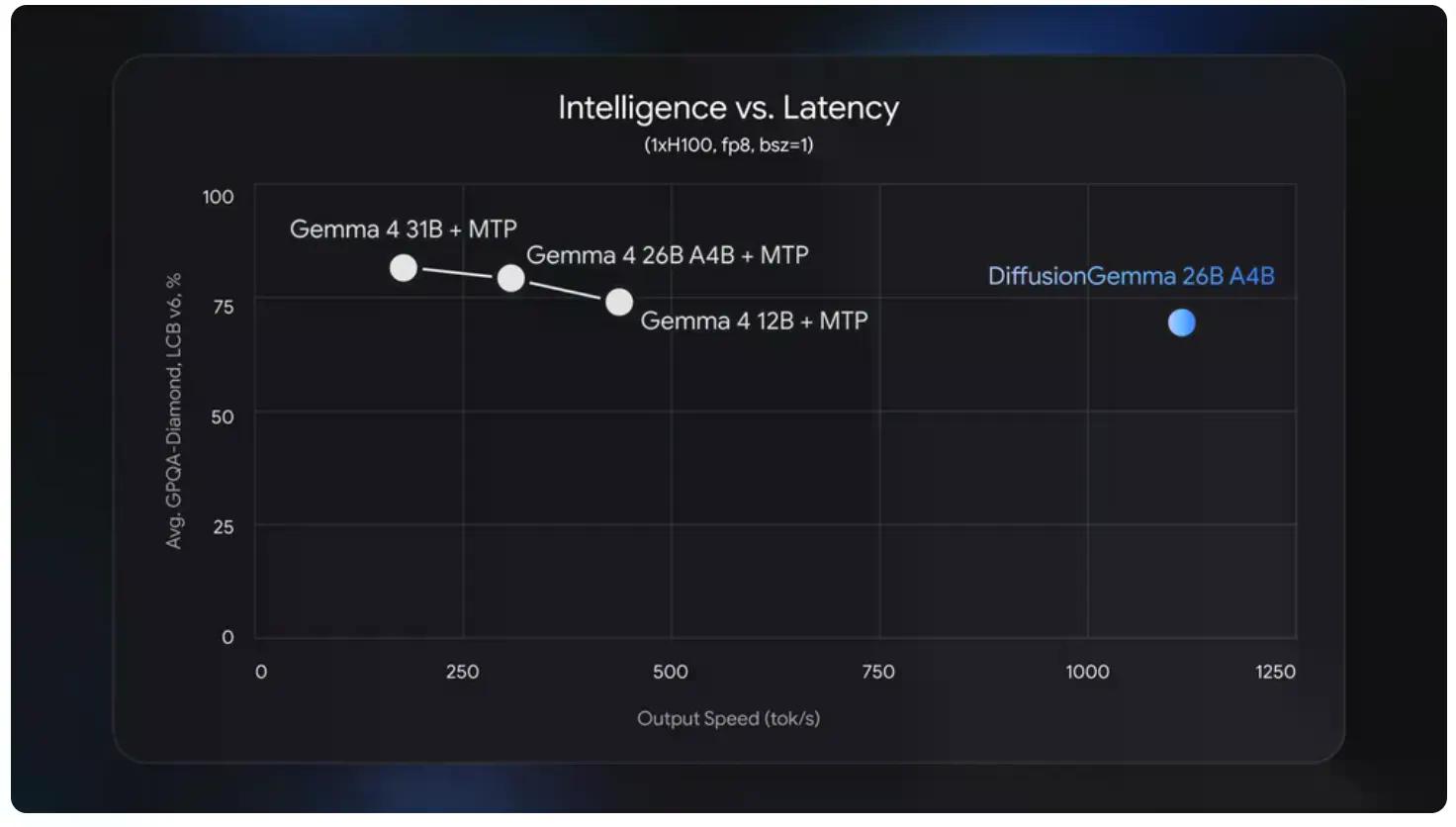
然而,一如既往,細節藏在魔鬼裡。根據 Google 的公告,該模型在 NVIDIA GeForce RTX 5090 上可達到「每秒 700+ 個 token」。其輸出品質也落後於標準的 Gemma 4。
Google 自己也承認,這是一個速度模型,而非品質升級。
你使用過的每一個大型語言模型(LLM)都像一台打字機。一次生成一個 token,每個詞都依賴前一個詞。這就是自回歸架構的運作方式。
DiffusionGemma 並非如此。它不循序生成 token,而是從平行處理的精煉亂碼文本塊開始。根據 Google 的開發者指南,它「從一塊隨機佔位符 token 的畫布開始」,並迭代鎖定確定的 token,直到整個區塊清晰成形。每次前向傳遞處理 256 個 token。這讓 GPU 保持忙碌。

其副作用是雙向注意力機制——每個 token 在生成時都能看到其他所有 token,這在自回歸模型中是不可能實現的(它們無法預見未來,即將編碼的內容)。這使得它在答案結尾約束開頭的任務上表現異常出色:例如程式碼補齊、結構化輸出、受限問題等。Google 曾微調一個版本來解決數獨,作為演示。基礎模型幾乎無法正確解決任何數獨題目。
而微調後的版本成功率達到 80%。
文字擴散(Text diffusion)多年來一直是研究專案。MDLM、SEDD、LLaDA、Dream 等學術模型證明了該方法在小規模應用中可行,但大多停留在概念驗證階段。Inception Labs 於 2026 年 2 月推出了 Mercury 2,這是第一個商用擴散推理模型,聲稱速度比速度優化的競爭對手快五倍。
但這些模型都不是開源權重,也沒有在 vLLM、Hugging Face Transformers 和 Unsloth 中提供初始支援。DiffusionGemma 是頂級實驗室首次發布的重要開源模型。
還有一個值得注意的歷史諷刺。圖像生成器最初是擴散模型(因此得名 Stable Diffusion),現在正轉向自回歸架構以獲得更好的品質。語言模型最初是自回歸模型,現在則正在嘗試擴散模型以提高速度。
高效運行 DiffusionGemma 需要一個「草稿器」(drafter)——這是一個輕量級模組,它平行地提出 token 區塊,然後主模型在一次前向傳遞中驗證這些區塊。這被稱為推測解碼(speculative decoding)。DFlash 是一個於 2026 年初發表的框架,它使用小型擴散模型作為草稿器,在某些任務上實現了超過 6 倍的加速。它是使這類模型變得實用的引擎。
問題在於:DiffusionGemma 需要一個特定的草稿器才能透過 MLX(Apple 針對 Apple Silicon 的機器學習框架)在本地運行。該模組目前尚未存在於任何公開版本的 mlx-lm、任何開放的拉取請求,或 LM Studio 的捆綁執行環境中。
我們嘗試透過 NVIDIA NIM 使用 Hermes 運行 DiffusionGemma。模型載入成功,但隨後出現錯誤:「代理初始化失敗:模型 google/diffusiongemma-26b-a4b-it 的上下文視窗為 8,192 個 token,低於 Hermes Agent 所需的最低 64,000 個 token。」
精確來說:DiffusionGemma 的實際上下文視窗為 256K 個 token。8,192 這個數字是 NVIDIA 預設設定有誤,而非模型的架構限制。
實際上,要為代理使用正確配置它,需要大多數日常用戶尚未掌握的手動操作,而 Hermes Agent 若無此配置根本無法初始化。如果代理無法啟動,平行處理的速度就毫無意義。
希望在未來幾天內,社群能提供更好的資源來運行這些模型。
擁有 NVIDIA RTX 4090 或 5090 硬體,並正在開發即時工具(如行內編輯器、自動完成、程式碼補齊、結構化生成)的開發者,是其目標受眾。正如 Decrypt 在五月份報導的,Google 一直在穩步推動在無需新硬體的情況下加速本地推論。
對於研究人員而言,雙向生成開啟了自回歸模型無法觸及的領域——例如蛋白質序列、數學圖形,以及任何位置 N 依賴於位置 N+50 的情況。這並非小事。
Google 於四月在 Apache 2.0 許可下發布了 Gemma 4,DiffusionGemma 延續了這一策略。截至今日,llama.cpp 已經有一個草稿 PR 開啟。當工具鏈迎頭趕上時,這將觸及更廣泛的受眾。
在配備強大獨立 GPU 的機器上,每秒 1,000 個 token 的速度將成為現實。
