
DeepSeek 捲土重來,而且是在 OpenAI 推出 GPT-5.5 幾小時後現身。巧合嗎?或許吧。但如果你是一家中國的 AI 實驗室,在過去三年中一直受到美國政府晶片出口禁令的打壓,你的時機感自然會變得非常敏銳。
這家位於杭州的實驗室今天發布了 DeepSeek-V4-Pro 和 DeepSeek-V4-Flash 的預覽版本,兩者均為開源權重模型,並具備一百萬 token 的上下文視窗。這意味著你基本上可以在模型崩潰之前,處理一個大約等同於《魔戒》三部曲大小的上下文。兩款模型的價格都遠低於西方任何同類產品,並且對於那些能夠在本地運行的人來說是免費的。
DeepSeek 上一次的重大顛覆發生在 2025 年 1 月的 R1,當時 Nvidia 的市值在一天之內蒸發了 6,000 億美元,投資者質疑美國公司是否真的需要如此鉅額的投資才能產出一個小型中國實驗室以極小成本實現的成果。V4 是一種不同的舉動:更安靜、更技術化,更專注於為實際建構 AI 的開發者提供效率。
在這兩款新模型中,DeepSeek 的 V4-Pro 是重量級產品,總共有 1.6 兆個參數。為了更清楚地說明,參數是模型用來儲存知識和識別模式的內部「設定」或「腦細胞」——模型的參數越多,理論上它能容納的資訊就越複雜。這使其成為迄今為止 LLM 市場中最大的開源模型。這個尺寸聽起來可能很荒謬,直到你發現它在每次推理過程中只啟動了 490 億個參數。
這就是 DeepSeek 自 V3 以來不斷改進的專家混合(Mixture-of-Experts)技巧:完整的模型就在那裡,但對於任何給定的請求,只有其相關部分會被喚醒。知識更多,計算成本不變。
DeepSeek 在 Huggingface 上的模型官方卡片中寫道:「DeepSeek-V4-Pro-Max,DeepSeek-V4-Pro 的最大推理努力模式,顯著提升了開源模型的知識能力,並牢固地確立了其作為當今最佳開源模型的地位。它在程式碼基準測試中取得了頂級性能,並顯著縮小了與領先閉源模型在推理和代理任務上的差距。」
V4-Flash 則是更實用的一款:總計 2,840 億個參數,其中 130 億個處於活躍狀態。它旨在更快、更便宜,根據 DeepSeek 自己的基準測試,它「在給予更大的思考預算時,達到了與 Pro 版本相當的推理性能」。
兩款模型都支援一百萬個 token 的上下文。這大約是 75 萬字——差不多是整個《魔戒》三部曲的篇幅,還多了一些。而且這是作為標準功能提供的,而非高級層級。
這是技術細節部分,專為技術愛好者或對模型背後魔力感興趣的人準備。DeepSeek 並沒有隱藏其秘密,所有資訊都可免費獲取——完整論文可在 Github 上找到。
標準的 AI 注意力機制——讓模型理解詞彙之間關係的機制——存在嚴重的擴展問題。每當上下文長度加倍時,計算成本大約會翻四倍。因此,在一百萬個 token 上運行模型,不僅比 50 萬個 token 貴兩倍,而是貴四倍。這就是為什麼長期以來,長上下文一直是實驗室添加的功能,然後在速率限制背後悄悄地限制。
DeepSeek 發明了兩種新的注意力類型來解決這個問題。第一種是「壓縮稀疏注意力機制」(Compressed Sparse Attention),它分兩步工作。它首先將 token 群組——比如每 4 個 token——壓縮成一個單一的條目。然後,它不關注所有這些壓縮的條目,而是使用一個「閃電索引器」(Lightning Indexer)只選擇與任何給定查詢最相關的結果。你的模型從關注一百萬個 token 變為關注一小部分最重要的區塊,就像一個圖書館員,他不必閱讀每一本書,但卻知道該查閱哪個書架。
第二種是「重度壓縮注意力機制」(Heavily Compressed Attention),它更具侵略性。它將每 128 個 token 壓縮成一個單一條目——沒有稀疏選擇,只是粗暴的壓縮。你會失去精細的細節,但能獲得一個極其便宜的全局視圖。這兩種注意力類型交替層次運行,因此模型既能獲得細節,也能獲得總體概覽。
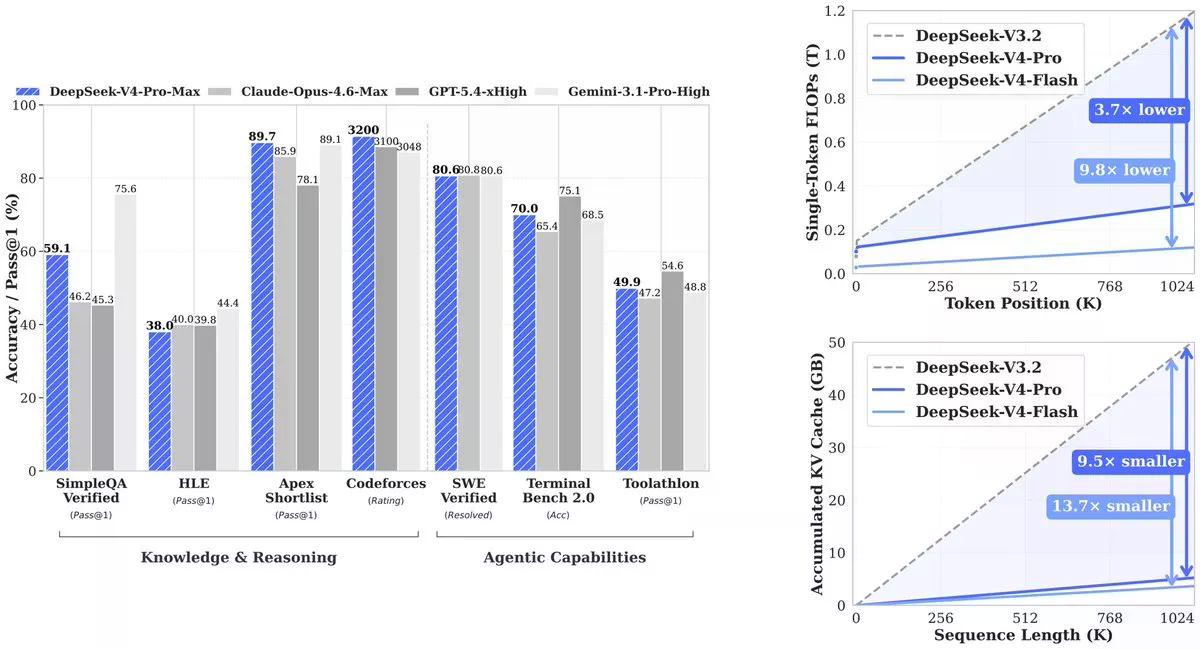
技術論文顯示,其結果是:在一百萬個 token 的情況下,V4-Pro 的計算量僅為其前身 (V3.2) 的 27%。KV 快取 (模型追蹤上下文所需的記憶體) 降至 V3.2 的 10%。V4-Flash 更進一步:計算量為 10%,記憶體為 7%。
這使得 DeepSeek 能夠以比競爭對手更低的每個 token 價格提供可媲美的結果。以美元計算:GPT-5.5 昨天發布時,每百萬輸入 token 5 美元,每百萬輸出 token 30 美元,而 GPT-5.5 Pro 的價格是每百萬輸入 token 30 美元,每百萬輸出 token 180 美元。
DeepSeek V4-Pro 的輸入價格為 1.74 美元,輸出價格為 3.48 美元。V4-Flash 的輸入價格為 0.14 美元,輸出價格為 0.28 美元。Cline 執行長 Saoud Rizwan 指出,如果 Uber 使用 DeepSeek 而非 Claude,其 2026 年的 AI 預算——據報導僅夠使用四個月——將可以使用七年。
deepseek v4 is now the cheapest sota model available at 1/20th the cost of opus 4.7.
for perspective, if uber used deepseek instead of claude their 2026 ai budget would have lasted 7 years instead of only 4 months. pic.twitter.com/i9rJZzvRBV
— Saoud Rizwan (@sdrzn) April 24, 2026
DeepSeek 在其技術報告中做了一件不尋常的事情:它公開了差距。大多數模型發布都只挑選他們獲勝的基準測試。DeepSeek 針對 GPT-5.4 和 Gemini-3.1-Pro 進行了全面的比較,發現 V4-Pro 的推理能力落後這些模型大約三到六個月,並仍將其發表。
V4-Pro-Max 實際獲勝的地方:Codeforces,一個競爭性程式設計基準測試,評分方式類似人類西洋棋。V4-Pro 獲得 3,206 分,在實際人類參賽者中排名約第 23 位。在 Apex Shortlist (一套精心策劃的困難數學和 STEM 問題) 上,它的及格率為 90.2%,優於 Opus 4.6 的 85.9% 和 GPT-5.4 的 78.1%。在 SWE-Verified (衡量模型能否解決來自真實開源儲存庫的實際 GitHub 問題) 上,它獲得 80.6% 的分數,與 Claude Opus 4.6 相當。
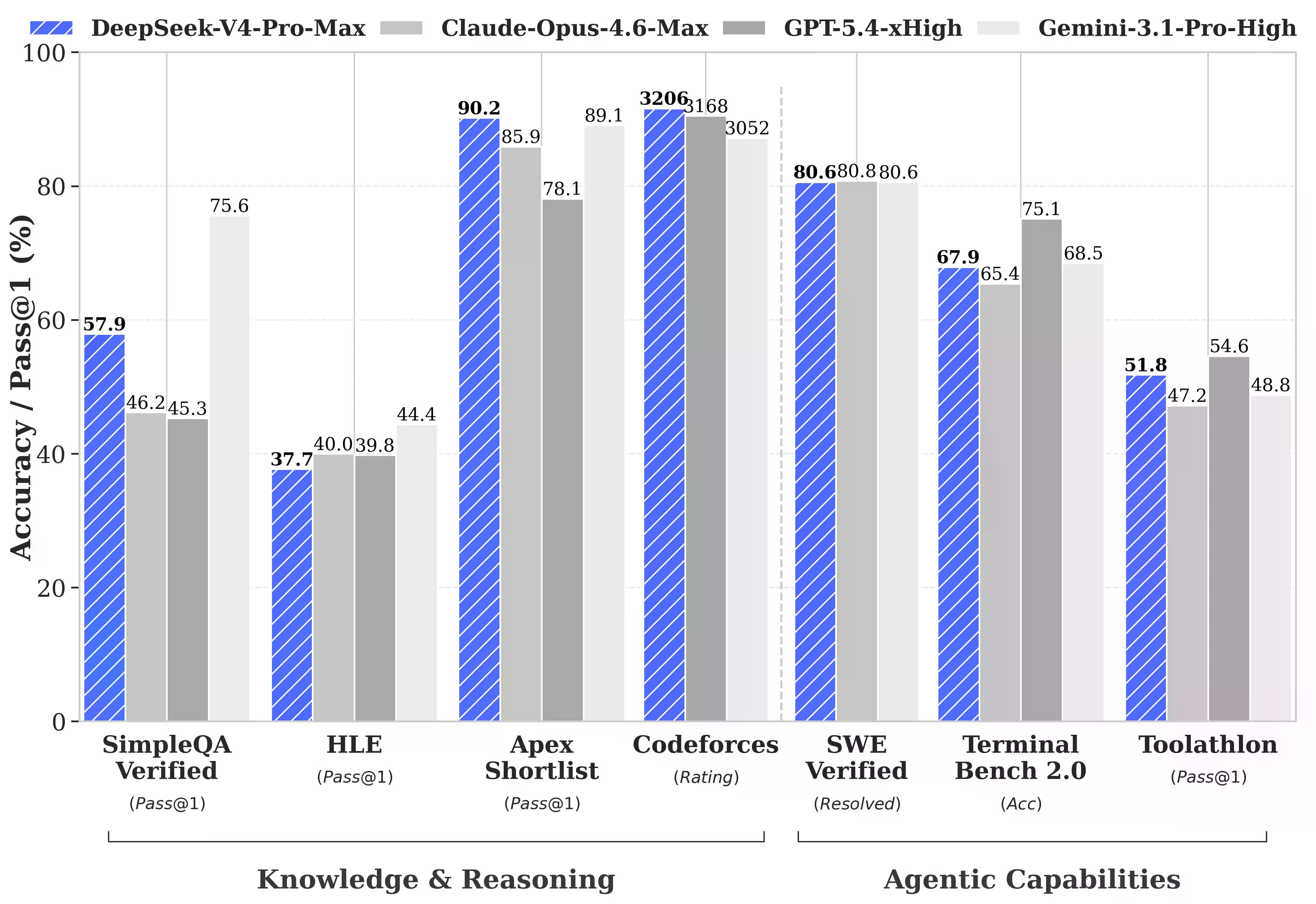
它落後的地方:多任務基準測試 MMLU-Pro (Gemini-3.1-Pro 為 91.0% vs V4-Pro 為 87.5%)、專家知識基準測試 GPQA Diamond (Gemini 94.3 vs V4-Pro 90.1),以及「人類最後的考試」(Humanity's Last Exam),這是一個研究生級別的基準測試,Gemini-3.1-Pro 的 44.4% 仍然擊敗了 V4-Pro 的 37.7%。
特別是在長上下文方面,V4-Pro 在 CorpusQA 基準測試 (模擬對一百萬個 token 進行真實文件分析的測試) 中領先開源模型並擊敗 Gemini-3.1-Pro,但在 MRCR (衡量模型在極長資料中檢索特定資訊的能力的測試) 中輸給了 Claude Opus 4.6。
對於實際交付產品的開發者來說,代理能力是本次發布的有趣之處。
V4-Pro 可以在 Claude Code、OpenCode 和其他 AI 程式碼工具中運行。根據 DeepSeek 對 85 位將 V4-Pro 作為其主要程式碼代理的開發者進行的內部調查,52% 的人表示它已準備好成為他們的預設模型,39% 的人傾向於肯定,不到 9% 的人表示否定。內部員工表示,它在代理程式碼任務上的性能超越了 Claude Sonnet,並接近 Claude Opus 4.5。
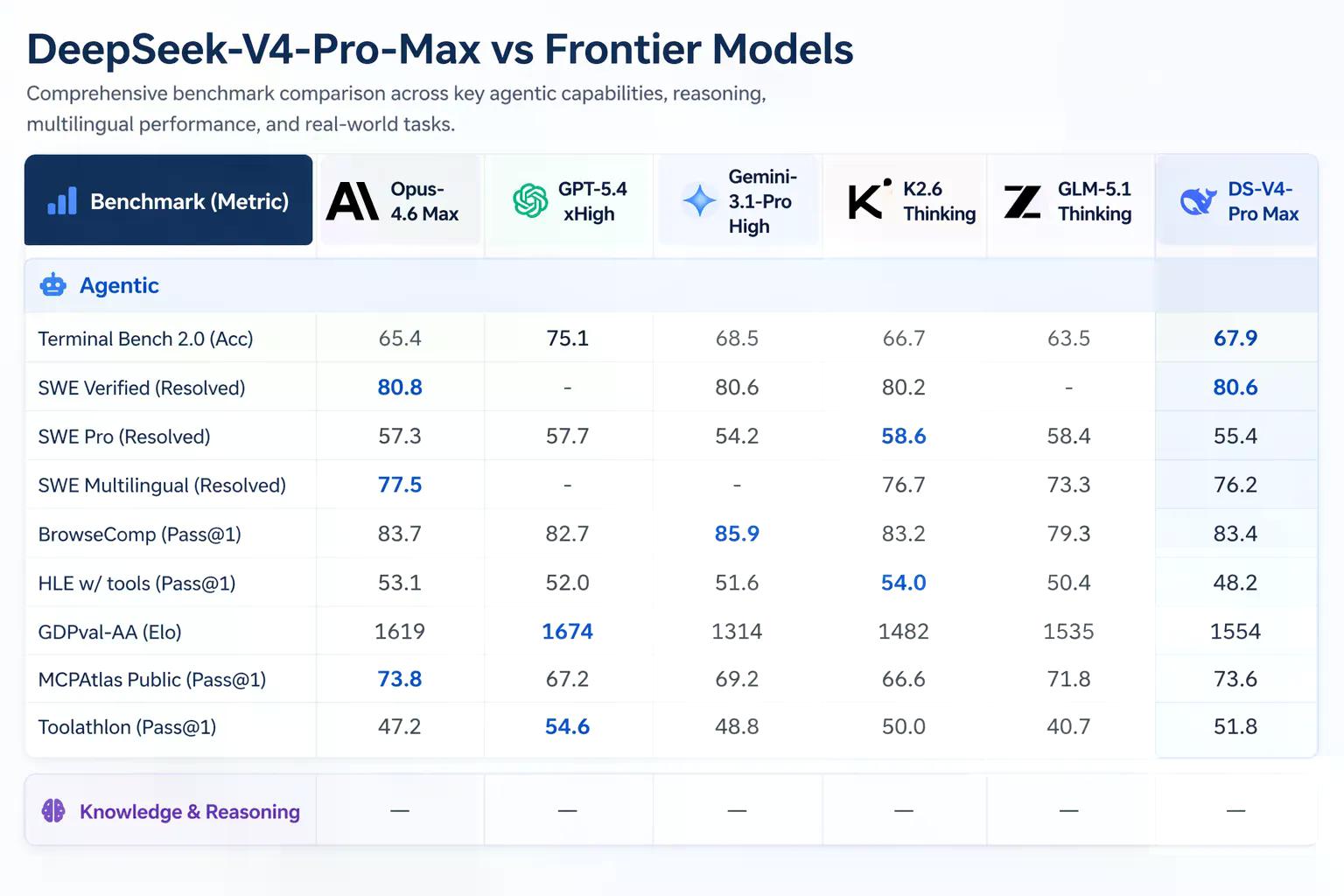
Artificial Analysis 是一家對 AI 模型進行獨立現實任務評估的公司,它將 V4-Pro 在 GDPval-AA 上的排名列為所有開源權重模型中的第一名——GDPval-AA 是一個透過 Elo 評分來測試金融、法律和研究等經濟上有價值的知識工作的基準。V4-Pro-Max 獲得 1,554 Elo 分數,領先於 GLM-5.1 (1,535) 和 MiniMax 的 M2.7 (1,514)。作為參考,Claude Opus 4.6 在同一基準測試中獲得 1,619 分——仍然領先,但差距正在縮小。
DeepSeek V4 Pro is the #1 open weights model on GDPval-AA, our agentic real-world work tasks evaluation@deepseek_ai has released V4 Pro (1.6T total / 49B active) and V4 Flash (284B total / 13B active). V4 is DeepSeek's first new size since V3, with all intermediate models… pic.twitter.com/2kJWVrKQjF
— Artificial Analysis (@ArtificialAnlys) April 24, 2026
DeepSeek 的 V4 還引入了「交錯思維」(interleaved thinking)功能。在以前的模型中,如果你運行一個進行多次工具調用的代理——例如,它搜尋網路,然後運行一些程式碼,然後再次搜尋——模型的推理上下文在回合之間會被清除。每一步新操作,模型都必須從頭開始重建其心智模型。V4 則保留了跨工具調用的完整思維鏈,因此一個 20 步的代理工作流程不會在半途遭受失憶症。對於任何運行複雜自動化管線的人來說,這比聽起來更重要。
自 2022 年以來,美國一直限制高端 Nvidia 晶片對中國的出口。聲稱的目標是減緩中國 AI 的發展,但晶片禁令並未阻止 DeepSeek,反而促使他們發明更高效的架構並建立國內硬體供應。
DeepSeek 並非在真空狀態下發布 V4——最近 AI 領域活動頻繁:Anthropic 於 4 月 16 日推出了 Claude Opus 4.7——《Decrypt》測試發現該模型在程式碼和推理方面表現強勁,且 token 使用量顯著。就在前一天,Anthropic 還持有 Claude Mythos,這是一個網路安全模型,他們表示由於其在自主網路攻擊方面的能力過於強大,無法公開發布。
小米於 4 月 22 日推出了 MiMo V2.5 Pro,全面邁向多模態——涵蓋圖像、音訊、視訊。其成本為每百萬 token 輸入 1 美元,輸出 3 美元。它在大多數程式碼基準測試中與 Opus 4.6 相當。三個月前,沒有人談論小米是一家前沿 AI 公司。現在,它發布競爭力模型的速度比大多數西方實驗室都快。
OpenAI 的 GPT-5.5 昨日推出,Pro 版本的輸出價格飆升至每百萬 token 180 美元。它在 Terminal Bench 2.0 (測試複雜命令行代理工作流程) 上擊敗了 V4-Pro (82.7% vs 70.0%)。但對於相同任務,它的成本明顯高於 V4-Pro。同一天,騰訊發布了 Hy3,這是另一個專注於效率的尖端模型。
那麼,有這麼多新模型可用,開發者真正想問的問題是:什麼時候溢價是值得的?
對於企業來說,這筆帳可能已經改變。一個在開源基準測試中領先、每百萬輸入 token 僅需 1.74 美元的模型,意味著六個月前昂貴的大規模文件處理、法律審查或程式碼生成管線現在變得便宜許多。一百萬個 token 的上下文意味著你可以在一個請求中輸入整個程式碼庫或監管文件,而不是將它們分塊處理。
此外,其開源特性意味著它不僅可以在本地硬體上免費運行,還可以根據公司的需求和用例進行客製化和改進。
對於開發者和個人建構者來說,V4-Flash 值得關注。其輸入價格為 0.14 美元,輸出價格為 0.28 美元,比一年前被認為是預算選項的模型還要便宜——而且它處理大多數任務的能力與 Pro 版本相當。DeepSeek 現有的 deepseek-chat 和 deepseek-reasoner 端點已分別在非思維模式和思維模式下路由至 V4-Flash,因此如果你使用 API,你已經在使用它了。
目前這些模型僅支援文字。DeepSeek 表示他們正在開發多模態功能,這意味著從小米到 OpenAI 等其他大型實驗室仍然具有這方面的優勢。兩款模型均採用 MIT 許可,並已在 Hugging Face 上發布。舊的 deepseek-chat 和 deepseek-reasoner 端點將於 2026 年 7 月 24 日停用。